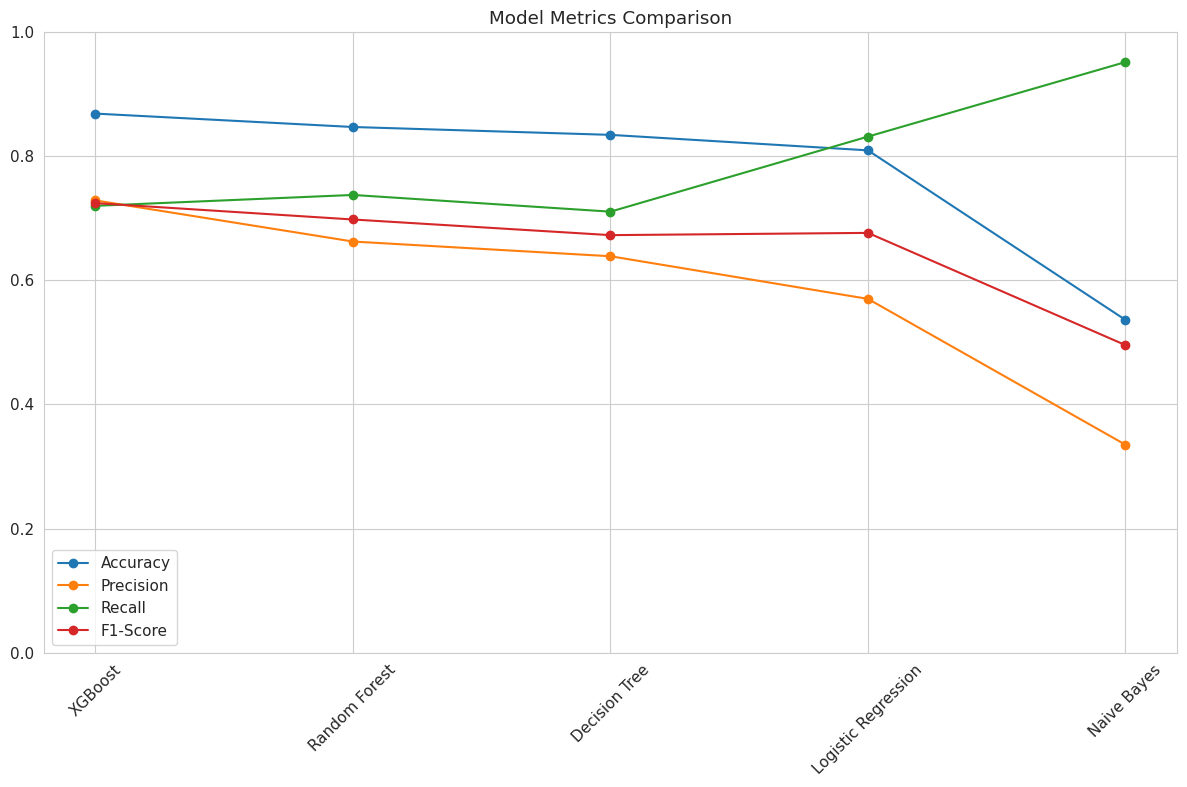
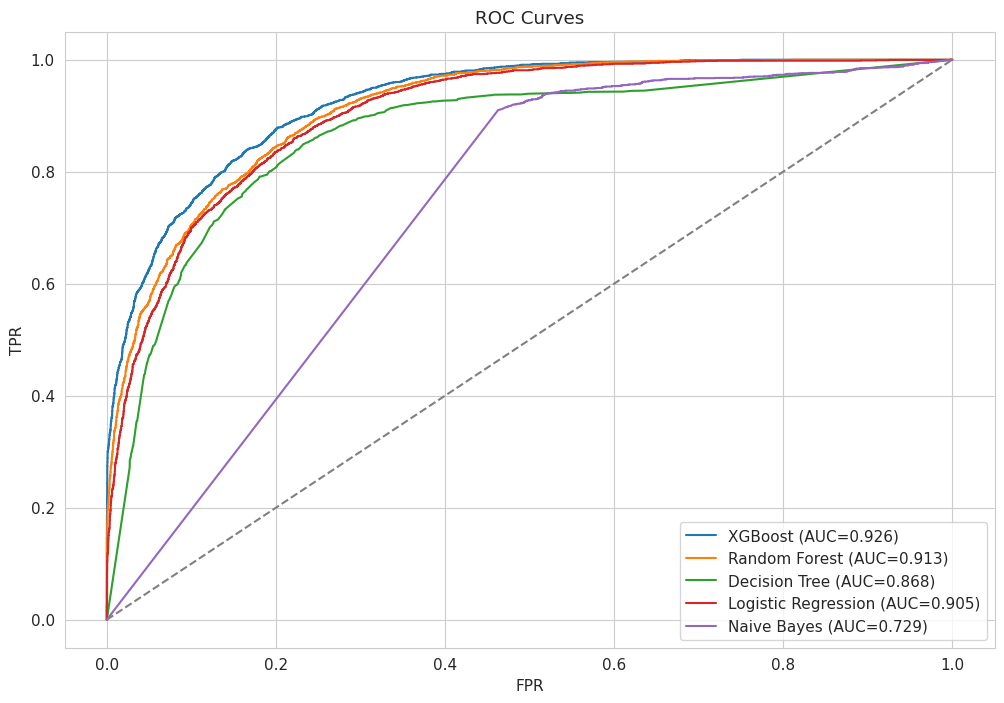
# model training
models = {
'Logistic Regression': (LogisticRegression(max_iter=1000), X1_train, y1_train, X1_test),
'Naive Bayes': (GaussianNB(), X1_train, y1_train, X1_test),
'Decision Tree': (DecisionTreeClassifier(max_depth=15), X2_train, y2_train, X2_test),
'Random Forest': (RandomForestClassifier(n_estimators=100, max_depth=15), X2_train, y2_train, X2_test),
'XGBoost': (xgb.XGBClassifier(eval_metric='logloss'), X2_train, y2_train, X2_test)
}
results, models_trained = {}, {}
for name, (model, Xtr, ytr, Xte) in models.items():
model.fit(Xtr, ytr)
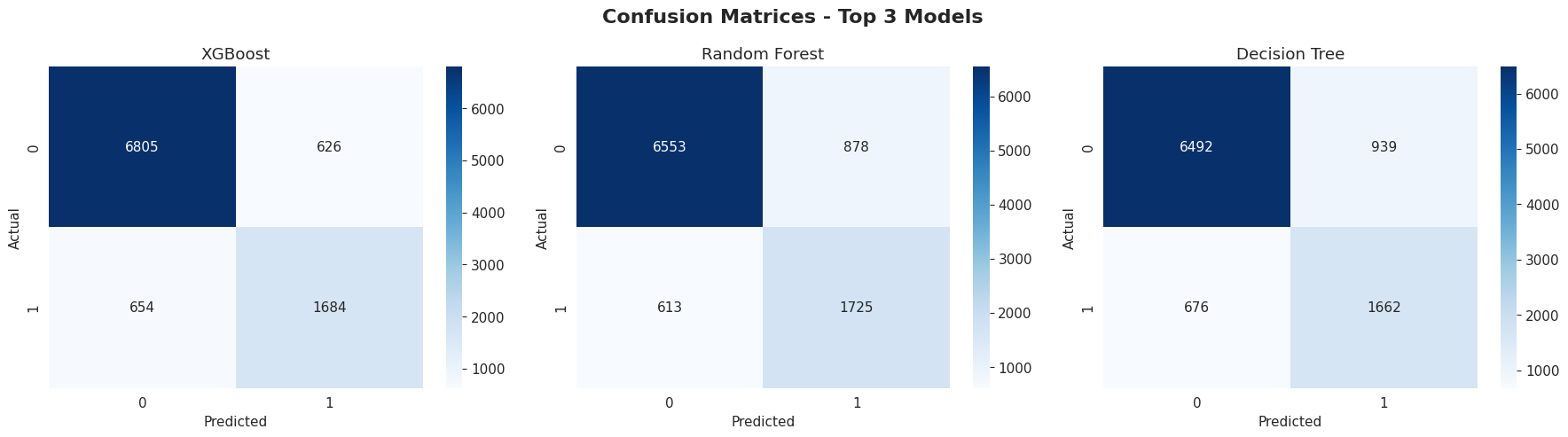
pred, prob = model.predict(Xte), model.predict_proba(Xte)[:,1]
results[name] = {
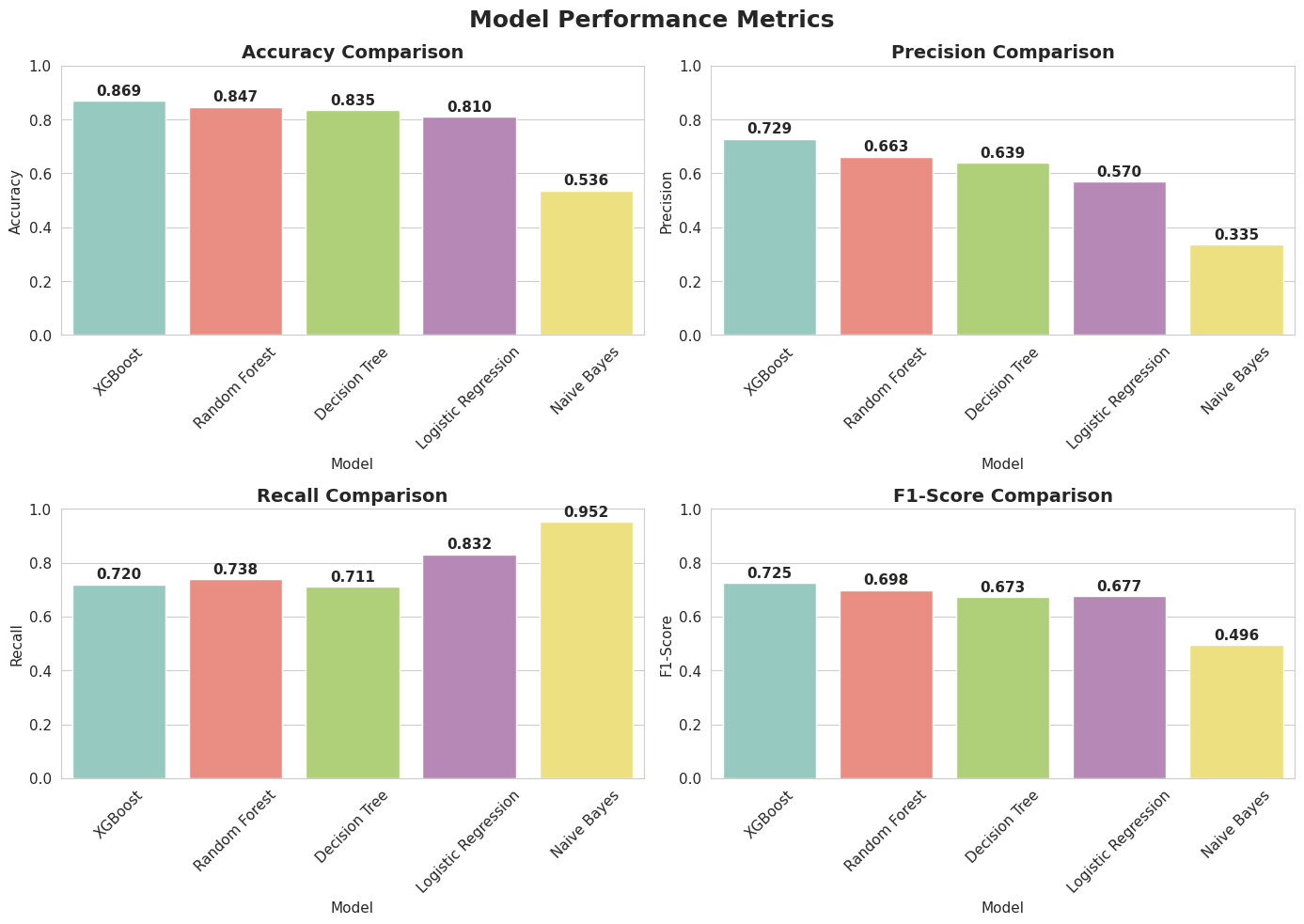
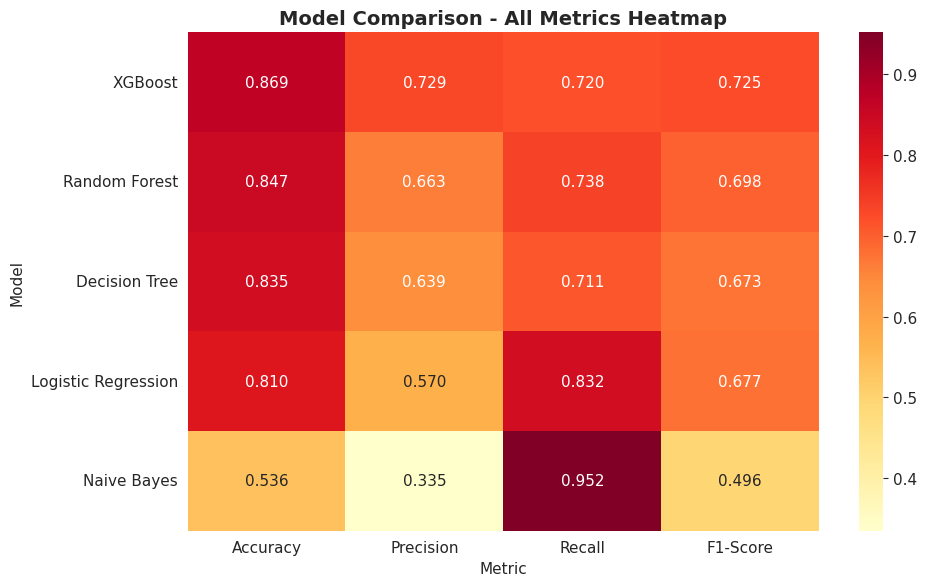
'Accuracy': accuracy_score(y_test, pred),
'Precision': precision_score(y_test, pred),
'Recall': recall_score(y_test, pred),
'F1-Score': f1_score(y_test, pred),
'pred': pred, 'prob': prob
}
models_trained[name] = model
df_res = pd.DataFrame(results).T.sort_values('Accuracy', ascending=False).reset_index().rename(columns={'index': 'Model'})